Interval Ropes
I recently solved a programming problem for which I couldn’t find a complete solution in the literature. What kind of data stucture would satisfy the following properties?
- It can store a set of non-overlapping intervals
- It can delete from the set of intervals, and will decrement subsequent intervals if the deletion point is before the last interval
- It can insert into the set of intervals, and will increment subsequent intervals if we inserted before the last interval
It is worth grounding these requirements in an actual use case. I had these requirements for a text editor that I am implementing. A text editor should support searching through a file and moving to the next/previous match, for which the set of intervals is helpful to represent the matched indices.
To understand the requirements around incrementing and decrementing, consider finding the search string world in the source string hello world. The search string matches starting from index 6 in the source string.
If we delete the space in the source string, then the match would start from index 5 instead. Alternatively, if we insert a space at the start of the source string, then the match would be at index 7. Without incrementing and deleting, the interval set would become inconsistent with the underlying source.
The data structure I arrived at for fulfilling thse requirements is inspired by the indexing system of Ropes, the classic data structure used for efficiently manipulating very large strings. In this post, I hope to explain how I adapted Ropes for this purpose, with the intention of showing how the classic Rope can be useful for cases beyond its original purpose.
It is worth noting that several alternative approaches exist. There are many string-search algorithms that use clever heuristics to reduce the time for a full string search by a constant factor. I am less interested in such algorithms because it is more common in text editors to edit text than to perform a new search, and I believe we can do better for that case.
How Traditional String-Based Ropes Work
To undersand how Ropes were adapted for the kind of interval set described above, it is helpful to briefly remind ourselves about how Ropes work in the first place.
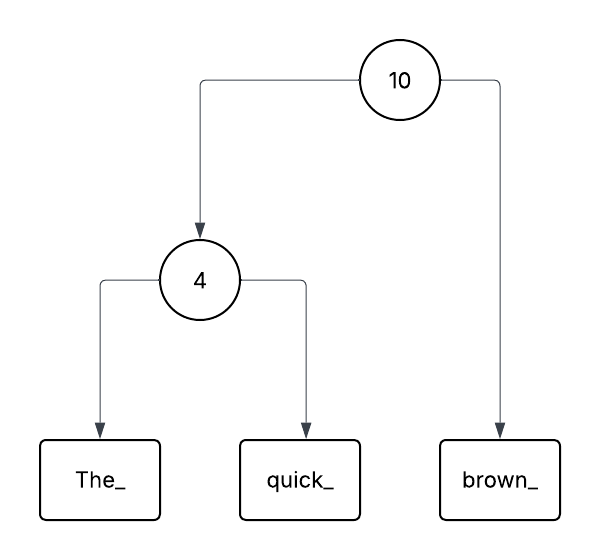
The above diagram shows an image of a Rope representing the text The_quiqk_brown_.
There are rectangles at the bottom containig strings. We call these leaf nodes. They contain the data we are interested in.
There are circle nodes with arrows pointing to leaf nodes or other circle nodes. We call these Concat nodes. They contain a pointer to a left node, a right node, and a number (called the node’s weight) representing the length of the data in the left node.
We can define a simple unbalanced Rope in Standard ML with the following recursive datatyoe declaation: datatype rope = Leaf of string | Concat of rope * int * rope.
We’ll look at some operations on this structure to understand how it works.
Indexing Into a Rope
Indexing into a Rope (or accessig a character) is very simple, but I would argue that it is the core operation that defines a Rope. If other operations change and the indexing system remains the samee then the data structure is still a Rope.
We have two general cases to handle for indexing.
- If we are at a Leaf node, we directly index into the string at this lode.
- If we are at a Concat node, we check if the requested index is less than the weight.
- If the requested index is less than the weight, than we recurse down the left node with the requested index.
- Otherwise, we subtract the weight from the requested index and recurse down the right node with this new number.
This lends itself to a very simple recursive implementation. In Standard ML, this would be implemented like so:
fun index (rope, requestedIndex) =
case rope of
Leaf string => String.sub (string, requestedIndex)
| Concat (left, weight, right) =>
if requestedIndex < weight then
index (left, requestedIndex)
else
index (right, requestedIndex - weight)
This is very simple to implement, but it can take a moment for us to understand why it works.
What does the weight have to do with indexing, and why do we sometimes subtract the weight against the requested index?
To answer this, we have to remember that the weight is the length of all nodes in the left subtree. If we subtract from the left subtreee’s length (the weight), then our new index will be relative to the right subtree, ignoring the length of all the strings in the left sobtree. This is exactly what we want when we recurse down the right node.
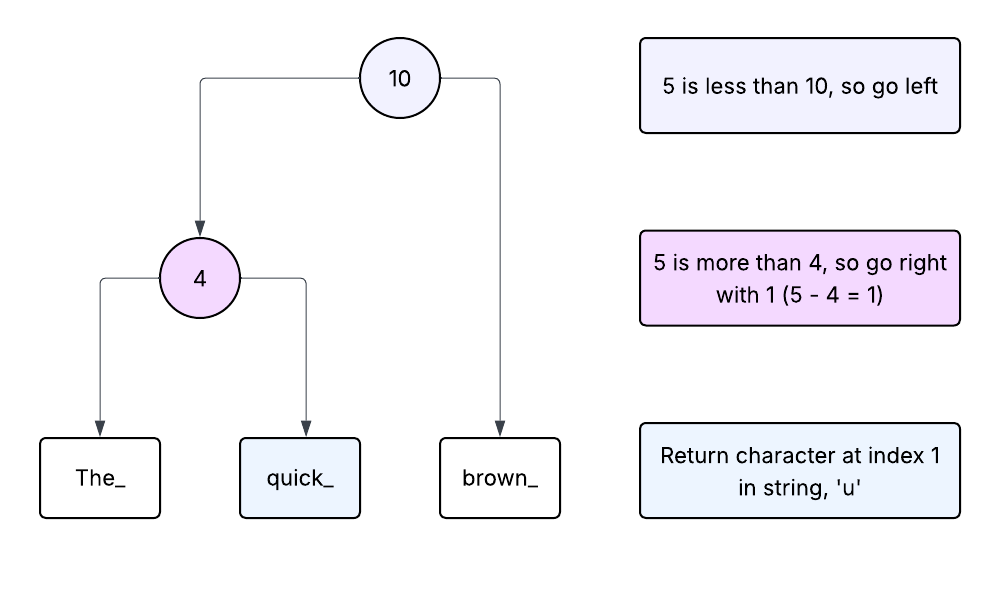
In the diagram above, I have tried to show an example of using this indexing algorithm to access the fifth character in the Rope. The steps and the node we are in at that step are correspondingly colour coded.
If you are feeling shaky about why this works, I recommend mentally trying to index characters at other positions following the same steps as the code given above. Your answer will always be the same as if you were directly indexing into the string The_quick_brown.
Calculating a Rope’s Length
Before we see how to concatnate to a Rope, we need to see how to calculate a Rope’s length first. The following diagram demonstrates this process.
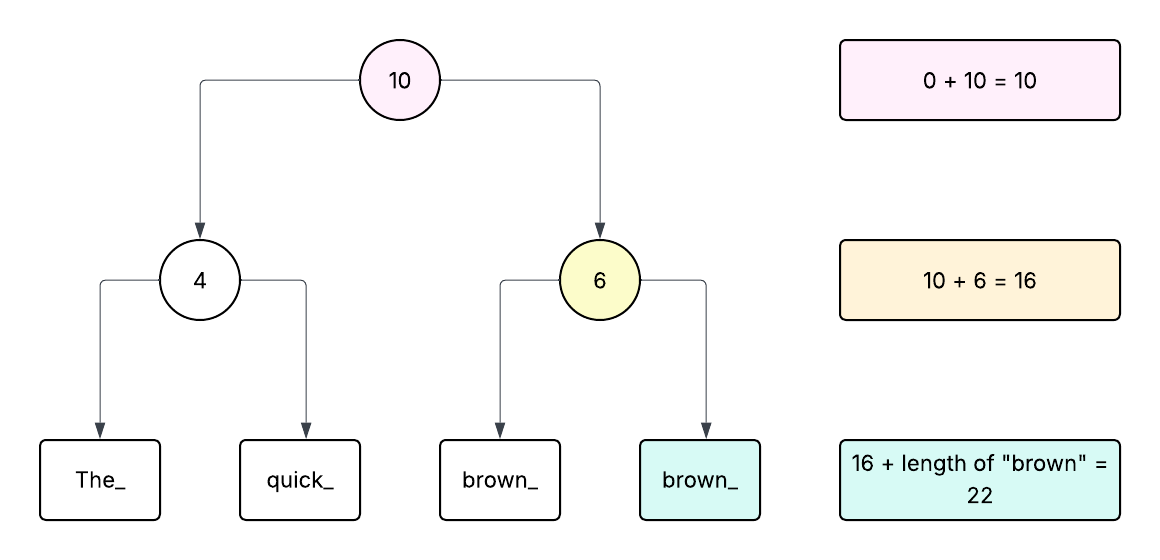
As shown in the above diagram, to calcolate the length of a Rope, we first descend down on all the nodes to the right, adding up all the weights on the way, and then we finally add the string’s length too.
This is how we calculate the Rope’s length. It makes sense, because the weights already contain the length of the left subtrees.
The below code implements this alyorithm.
fun helpLength (rope, acc) =
case rope of
Leaf string => acc + String.size string
| Concat (left, weight, right) => helpLength (right, weight + acc)
fun length rope = helpLength (rope, 0)
The helpLength function uses tail-recursion {taking in an accumulator argument) for efficiency, and the length function calls helpLenth with a default value of 0 so that we don’t need to supply 0 every time we want to get the length. However, those are incidental details.
Concatenating Ropes
The high level insert and delete functions on Ropes are implemented through a series of splitting and cncatenating Ropes.
We focus here just on concatenation for now.
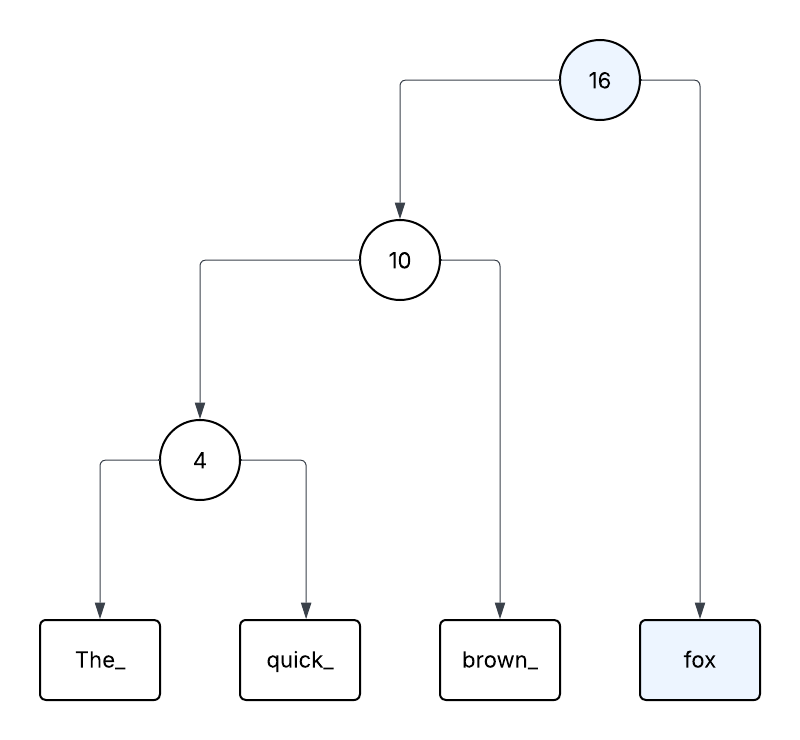
The concatenation function takes a left and a right Rope, and joins them by creating a new Concat node which contains the length of the length Rope, and pointers to both Ropes.
fun concatenate (left, right) =
Concat (left, length left, right)
Splitting a Rope
Splitting a Rope means extracting a portion of the Rope but with some string data left out of it.
We have two splt functions for different use cases:
splitKeepingStartwhich returns a section of a Rope from the beginning to some given indexsplitKeepingEndwhich returns a section of a Rope from some given index to the end of a Rope
These functions are the same as the index algorithm, with one difference: we return a section of the original Rope instead of a character.
When the recursion in this function unrolls, we make a copy the current node, except that our new copy replaces the node that we descended with the Rope node returned from the recursion.
fun splitKeepingStart (index, rope) =
case rope of
Leaf string =>
let
(* get a substring of original string, and return it in a Rope node *)
val substring = String.substring (string, 0, index)
in
Leaf substring
end
| Concat (left, weight, right) =>
if index < weight then
(* split left node. We do not need to create a new Concat node
* because Concat nodes only exist to join left and right nod es together
* and we do not need the right node since we are only keeping the left portion *)
splitKeepingStart (index, left)
else
let
(* split right node and return new Concat node with result *)
val newRight = splitKeepingStart (index - weight, right)
in
Concat (left, weight, newRight)
end
I have written a function to split the left section (from the start to some specified index) above.
I have opted for code comments rather than diagrams here, because there is nothing conceptually new to show.
We use the indexing algorithm to travel down the nodes, and we just copy data on the way up.
fun splitKeepingEnd (index, rope) =
case rope of
Leaf string =>
let
(* copy string from index to end of string *)
val length = String.size string - index
val substring = String.substring (string, index, length)
in
Leaf substring
end
| Concat (left, weight, right) =>
if index < weight then
let
val newLeft = splitKeepingEnd (index, left)
(* since we are keeping right side of Rope and removing part lefnt side,
* we have to recalculate the weight, which represents the left side's length *)
val newWeight = length newLeft
in
Concat (newLeft, newWeight, right)
end
else
(* we are splitting right node to end of Rope
* so we do not need the left node, or the Concat node that joins both nodes *)
splitKeepingEnd (index - weight, right)
An implementation of the splitKeepingEnd function, which splits (keeps data) from a given index to the end of the Rope, is above.
The only thing worth noting is that we adjust the weight if we descend down the left node. This is because we would have removed some part of the left node in that case, and the weight (the length of the left node) is different now. If we do not do this, our indexing algorithm would no longer work because the weight metadata would become incosistent.
Insertion and Deletion
With the splitting and concatenation functions in place, we’re near the end of our Rope implementation. We just have two high-level functions left.
fun insert (index, stringToInsert, rope) =
let
val left = splitKeepingStart (index, rope)
val right = splitKeepingEnd (index, rope)
val insertRope = Leaf stringToInsert
in
concatenate (
concatenate (left, insertRope),
right
)
end
The insert function takes an index to insert at, a string to insert, and a Rope to insert into. It returns a Rope with the string inseerted.
It works in a simple way. We split the Rope into left and right parts at some index, concatenate the new string which is a Rope now) to the left Rope, and then cocatenate the right Rope to this.
fun delete (deleteStart, deleteLength, rope) =
let
(* index to stop deleting at *)
val deleteEnd = deleteStart + deleteLength
val left = splitKeepingStart (deleteStart, rope)
val right = splitKeepingEnd (deleteEnd, rope)
in
concatenate (left, right)
end
The delete function is even simpler than the inesert function. We split the Rope into two halves we would like to keep, and then concatentae these two halves.
Performance Concerns in Implementation
I have focused on Ropes conceptually and disregarded performance entirely, but the Rope implementation above can be very inefficient. There are two reasons for this:
- There is no attempt to balance the Rope
- Short strings in adjacent nodes are not joined to form a single node
My reason for disregarding performanoe is that this post attempts to explain Ropes conceptually and how they can be adapted. Other conerns get in the way of that purpose.
Balancing Ropes
Because of the lack of balancing, the Rope can degnenerate into a linked list taking O(n) time for operations in the worst case, instead of O(log n). This can have a huge impact on degrading performance on larger Ropes.
Balancing Ropes is an exercise for the reader. Different balancing algorithms (AVL Trees, Red-black Trees, 1-2 Brother Trees) can be adapted to store Ropes.
I will provide a few hints on implementing a balanced Rope:
- A balanced Rope should update the weight of Concat nodes on tree rotations
- A balanced Rope must follow the same indexing system, but the inserting and deleting functions might not be implemented by splitting and concatenating nodes, as it is harder to ensure balacing if this is done.
I am guessing that adapting Trees of Bounded Balance, as described by Stephn Adams, would be the easiest way to implement balanced Ropes, as the implementation for this kind of tree makes use of splitting and concatenation functions internally, but this is only a guess.
Joining Short Strings
If we have adjacent nodes containing short strings below some length, it is preferable to join them into a single node.
There are two benefits, both improving the constant time performance, of doing so:
- We have fewer nodes in the Rope, which means less pointer-chasing to get to our desired Leaf
- We have better cache locality. Modern computers benefit from data being phsically close together in memory. A string’s individual characters are close together, but pointers to nodes are not necessarily close.
These are constant-time optimisations and don’t change the asymptootic complexity, but they can have a big impact on performance in practice.
Full String Rope Code
The full code for the String Rope is below. We also provide a signature describing the public API that can be used to query and manipulate the Rope.
signature STRING_ROPE =
sig
type t
val fromString: string -> t
val index: int * t -> char
val length: t -> int
val insert: int * string * t -> t
val delete: int * int * t -> t
end
structure StringRope :> STRING_ROPE =
struct
datatype rope = Leaf of string | Concat of rope * int * rope
type rope = t
(* creates a rope from a string *)
fun fromString string = Leaf string
fun index (rope, requestedIndex) =
case rope of
Leaf string => String.sub (string, requestedIndex)
| Concat (left, weight, right) =>
if requestedIndex < weight then
index (left, requestedIndex)
else
index (right, requestedIndex - weight)
fun helpLength (rope, acc) =
case rope of
Leaf string => acc + String.size string
| Concat (left, weight, right) => helpLength (right, weight + acc)
fun length rope = helpLength (rope, 0)
fun concatenate (left, right) =
Concat (left, length left, right)
fun splitKeepingStart (index, rope) =
case rope of
Leaf string =>
let
(* get a substring of original string, and return it in a Rope node *)
val substring = String.substring (string, 0, index)
in
Leaf substring
end
| Concat (left, weight, right) =>
if index < weight then
(* split left node. We do not need to create a new Concat node
* because Concat nodes only exist to join left and right nod es together
* and we do not need the right node since we are only keeping the left portion *)
splitKeepingStart (index, left)
else
let
(* split right node and return new Concat node with result *)
val newRight = splitKeepingStart (index - weight, right)
in
Concat (left, weight, newRight)
end
fun splitKeepingEnd (index, rope) =
case rope of
Leaf string =>
let
(* copy string from index to end of string *)
val length = String.size string - index
val substring = String.substring (string, index, length)
in
Leaf substring
end
| Concat (left, weight, right) =>
if index < weight then
let
val newLeft = splitKeepingEnd (index, left)
(* since we are keeping right side of Rope and removing part lefnt side,
* we have to recalculate the weight, which represents the left side's length *)
val newWeight = length newLeft
in
Concat (newLeft, newWeight, right)
end
else
(* we are splitting right node to end of Rope
* so we do not need the left node, or the Concat node that joins both nodes *)
splitKeepingEnd (index - weight, right)
fun insert (index, stringToInsert, rope) =
let
val left = splitKeepingStart (index, rope)
val right = splitKeepingEnd (index, rope)
val insertRope = Leaf stringToInsert
in
concatenate (
concatenate (left, insertRope),
right
)
end
fun delete (deleteStart, deleteLength, rope) =
let
(* index to stop deleting at *)
val deleteEnd = deleteStart + deleteLength
val left = splitKeepingStart (deleteStart, rope)
val right = splitKeepingEnd (deleteEnd, rope)
in
concatenate (left, right)
end
end
From String Ropes to Interval Ropes
We covered the basics of how classic Ropes work above, but the purpose of this post is to describe how Ropes can provide a useful foundation for use cases other than strings.
We do that now by exploring a particular adaptation satisfying the properties described at the start of this post.
An Interval Rope is represented through the following data type for these examples:
datatype interval_rope =
Concat of interval_rope * int * interval_rope
| Leaf of {startIdx: int, endIdx : int}
type t = interval_rope option
The only real differences here are:
- That the Leaf stores an interval objeot (containing a start and finish index) instead of a string.
- The Rope is wrapped in an option type to represent the null case where there are no intervalsis
The diagram below depicts an Interval Rope.
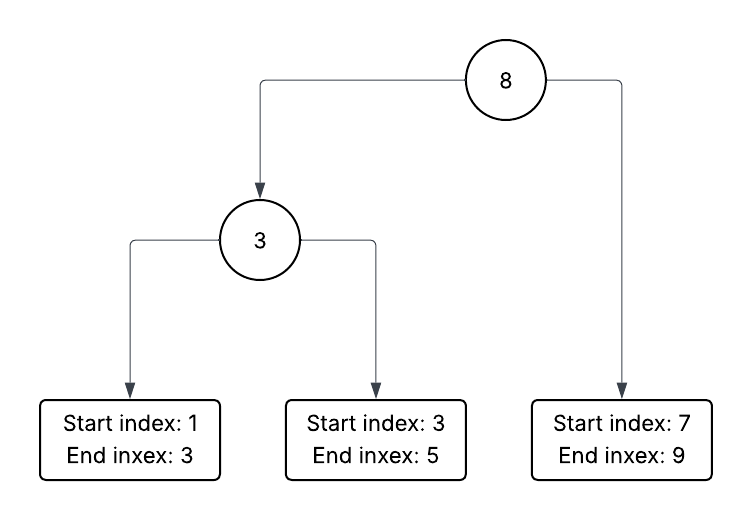
As we can see, the Conoat nodes now contain the largest end index in any interval.
The public API of our Interval Rope is described by the following signature:
signature INTERVAL_ROPE =
sig
type t
val empty: t
val hasIntervalAtIndex: int * t -> bool
val prevMatch: int * t -> {startIdx: int, endIdx: int} option
val incrementAt: int * int * t -> t
val delete: int * int * t -> t
val insert: {startIdx: int, endIdx: int} * t -> t
end
Indexing Into an Interval Rope
There are two differences in how indexing works.
- When we are at a Leaf, we check if our current index is within the interval here, returning true if so or false if not.
- We previously returned a character instead of a boolean when indexing into String Ropes
- Since the Interval Rope’s weight is the largest index, we descend down the left node if our index argument is less than or equal to the weight.
- This is different from how we index String Ropes because the weight of a String Rope is a length number rather than an actual index in the string.
The following code indexes into an Interval Rope to cheok if the index is contained in any interval.
fun uHasIntervalAtIndex (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
startIdx <= index andalso endIdx >= index
| Concat (left, weight, right) =>
if index <= weight then
uHasIntervalAtIndex (index, left)
else
uHasIntervalAtIndex (index - weight, right)
fun hasIntervalAtIndex (index, rope) =
case rope of
SOME rope => uHasIntervalAtIndex (index, rope)
| NONE => false
With the code samples for the Interval Rope, the high-level functions in the public API always pattern match on the option type and delegate the actual logic to a helper function. The names of the helper functions will often start with u, meaning unwrapped`.
Retrieving the Largest Matching Index
Instead of calculating the length like with String Ropes, we want to get the largest matching index for Interval Ropes. (The largest matching index means the highest index of any interval in the Rope.)
fun uLargestIdx (rope, acc) =
case rope of
Leaf {startIdx, endIdx} => endIdx + acc
| Concat (left, weight, right) =>
uLargestIdx (right, acc + weight)
fun largestIdx rope =
case rope of
SOME rope => uLargestIdx (rope, 0)
| NONE => 0
Again, the code here is almost exactly the same as getting the length of a String Rope. Except for how we pattern match on the option type first, the only difference is that the Leaf case adds the endIdx to the accumulator, instead of adding the string’s length to the accumulator.
Retrieving the Smallest Matching Index
We have a new function specific to Interval Ropes: retrieving the smallest index contained in any interval. We will describe how this function is used later, when we implement our high-level insert and delete functions.
We retrieve the smallest matching index by descending to the leftmost Rope, and then returning the startIdx when we eventually reach a Leaf.
fun smallestIdx rope =
case rope of
Leaf {startIdx, endIdx} => startIdx
| Concat (left, weight, right) => smallestIdx left
Retrieving the smallest matching index is not part of our public API and therefore does not need to deal with the option type, but we might want to make it part of our public API depending on our requirements, in which case we would unwrap the option type.
Concatenting Interval Ropes
The concatenate function for Interval Ropes is the same as that for String Ropes.
fun concatenate (left, right) =
Concat (left, uLargestIdx (left, 0), right)
Since concatenation is an implementation detail and not part of our public API, we don’t need to unwrap and pattern match against its arguments. We can make sure that we have unwrapped versions of the arguments when we make calls to it internally.
Splitting Interval Ropes
We can split Interval Ropes using a method similar to the one we used for splitting String Ropes. However, there are a few edge cases we need to handle for each splitting function.
- The given index may not include the interval at the Leaf node. We signal this by returning an
optiontype. - We have to handle the
NONEcase in recursive calls from Concat nodes. We may decide to delete theConcatnode depending on the split direction, or we might return the subtree we did not descend down.
These constraints are quite abstract. Let’s make them concrete by discussing each split function separately.
Splitting while keeping the start
When we are splitting and keeping the start of the Interval Rope to the given index, we want to return SOME for the Leaf node when the given index is after the interval at this node. We return NONE otherwise.
There are two reasons for only returning SOME when the index is after the interval.
The first reason is because this specific split function is meant to delete everything that is after the given index.
The second reason is more use-case dependent. In my use case where I want to keep a list of intervals matching a search query on some text, I need to remove an interval if a split-index is inside it. This is because it is possible the search string no longer matches that piece of text, so we remove it. In other use cases, it is possible that you instead want to keep the node and interval if the index is inside.
In any event, the way that we handle the option type in Concat nodes remains the same, regardless of our use case. The Concat node needs to be adjusted to handle the option type.
- When we receive a
NONEresult after descending down on the right child, we return this Concat node’s left child. We do this because the right child contains no intervals prior to the given index, but the left child does, so we only keep the left child. - When we receive a
SOMEresult after descending down on the right child, we replace the current right child with the subtree in the result. - When we descend down the left child, we immediately return whatever result our recursion has given us, whether that is
SOMEorNONE. In theNONEcase, we want to tell the parent that there were no intervals in the left child and this Concat node is to be deleted. In theSOMEcase, we want to tell the parent to only keep the result of descending down the left subtree, discarding the right child. Returning the result immediately accomplishes both of these.
fun splitKeepingStart (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
if index > endIdx then
SOME rope
else
NONE
| Concat (left, weight, right) =>
if index <= weight then
splitKeepingStart (index, left)
else
let
val result = splitKeepingStart (index - weight, right)
in
case result of
SOME newRight => SOME (Concat (left, weight, newRight))
| NONE => SOME left
end
The above code implements this particular split function as required.
Splitting while keeping the end
There is less theoretical explanation for splitting in the other direction, keeping a given index to the end of the Rope. We just reverse the direction.
- For the Leaf case, we return
SOMEif the given index is before the interval’s start - When we descend down the left subtree of a Concat node, we replace the left node if the result is
SOMEor return the right node if the result isNONE. - When we descend down the right subtree of a Concat node, we immediately return whatever result our recursion gave us.
This is implemented by the code below.
fun splitKeepingEnd (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
if index < startIdx then
SOME rope
else
NONE
| Concat (left, weight, right) =>
if index <= weight then
case splitKeepingEnd (index, left) of
SOME newLeft => SOME (Concat (newLeft, uLargestIdx (newLeft, 0), right))
| NONE => SOME right
else
splitKeepingEnd (index - weight, right)
Incrementing and Decrementing an Interval Rope
The introduction to this post explained the need for incrementing and decrementing an Interval Rope for the use case in question. When text is deleted from our string (or other text data structure), we want to decrement matches that appear after the deletion point, by the length of text that was deleted. Similarly, inserting a character before a match should cause match indices to be incremented.
The idea for decrementing an Interval Rope is as follows:
- For Leaf nodes, we subtract the
startIdxandendIdxby some amount. - For Concat nodes, we recurse down the left child. When the recursive call returns, we call
uLargestIdxto get the left child’s new weight, and then we return the new left child with the new weight and the old right child.
That is all we have to do in order to decrement. This process will have a knock-on effect on all the other nodes in the Interval Rope too, where the absolute indices they represent are also decreemented, although we did not touch those other intervals or nodes.
The diagram below illustrates this process.

The above diagram shows the first character of a String Rope being deleted, and the leftmost node in an Interval Rope being decremented as a result. While only relative indices are in this diagram, we can mentally convert these to absolute indices. If we do so, we see that the whole Interval Rope is decremented, despite us touching only one interval.
Remember the relative indexing system for Ropes: the absolute index can be calculated by summing all the weights on the path (only when we descend to the right child) to the Leaf node in question, and then summing the index at the Leaf node. This property is what creates the knock-on effect we observe here.
Code that implements the decrement function is below.
fun decrement (decrementBy, rope) =
case rope of
Leaf {startIdx, endIdx} =>
Leaf {
startIdx = startIdx - decrementBy,
endIdx = endIdx - decrementBy
}
| Concat (left, weight, right) =>
let
val newLeft = decrement (decrementBy, left)
val newWeight = weight - decrementBy
in
Concat (newLeft, newWeight, right)
end
Incrementing a value is implemented in exactly the same way, except that we add to the weights and to the interval we reach while travelling to the leftmost node.
We could just pass a negative number to our decrement function (because subtracting by a negative number is the same as adding), or we might code an explicit increment function like the following.
fun increment (incrementBy, rope) =
case rope of
Leaf {startIdx, endIdx} =>
Leaf {
startIdx = startIdx + incrementBy,
endIdx = endIdx + incrementBy
}
| Concat (left, weight, right) =>
let
val newLeft = increment (incrementBy, left)
val newWeight = weight + incrementBy
in
Concat (newLeft, newWeight, right)
end
Since incrementing is part of our public API, the increment function above is a helper function to the incrementAt function below.
fun incrementAt (idx, incrementBy, rope) =
case rope of
SOME rope =>
let
val left = splitKeepingStart (idx, rope)
val right = splitKeepingEnd (idx, rope)
in
case (left, right) of
(SOME left, SOME right) =>
let
val newRight = increment (incrementBy, right)
in
SOME (concatenate (left, newRight))
end
| (SOME left, NONE) =>
(* nothing to increment since no intervals after index *)
SOME left
| (NONE, SOME right) =>
(* just incremet right and return without concatenating, since there is no left *)
SOME (increment (incrementBy, right))
| (NONE, NONE) =>
(* nothing remains after splitting, so return nothing *)
NONE
end
| NONE => NONE
It the Rope is SOME, then this incrementAt function just splits the Rope into two halves at the given index, increments the right half, and joins both Ropes back together. This lets us increment intervals after a given index. We do this before inserting.
Retrieving the next and previous intervals
These are the last two helper functions that we need in order to implement our high level insert and delete functions.
The essence of retreiving the next and previous intervals is the same at its core as indexing, but there are a number of implementation differences, some common to both functions and some which are unique to the function in question.
The common differences from indexing are:
- We return an
optiontype, possibly containing the interval, indicating if such an interval exists - We return the interval’s absolute index by adding the current node’s weight to an accumulator (only when we descend down a node’s right child), and then add the accumulator to the interval’s relative indices
- We sometimes descend down the other node when we receive
NONEat a Concat node, like we do in our splitting functions
Finding the next match
There are two things that we need to do only when looking for the next match.
In a Leaf node, we return SOME and consider this the next interval only if the argument index is less than the interval’s start index. Otherwise, this is either the current interval or the previous one, and we return NONE in either of these two cases.
In a Concat node, we use recursion to index as usual, However, if we descend down the left node and see that the result is NONE, we return the smallest interval in the right subtree instead,
This is implemented by the code below.
fun smallestInterval (rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
{startIdx = startIdx + acc, endIdx = endIdx + acc}
| Concat (left, weight, right) => smallestInterval (left, acc)
fun helpNextMatch (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
if index < startIdx then
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
else
NONE
| Concat (left, weight, right) =>
if index < weight then
case helpNextMatch (index, left, acc) of
SOME interval => SOME interval
| NONE => SOME (smallestInterval (right, acc + weight))
else
helpNextMatch (index - weight, right, acc + weight)
fun nextMatch (index, rope) = helpNextMatch (index, rope, 0)
We have some helper functions here. The smallestInterval function returns the smallest interval in the given sub-rope, nextMatch wraps helpNextMatch so we don’t need to pass an accumulator to the latter, and helpNextMatch contains the logic described above. There isn’t much new here.
Finding the previous match
Once more, there are two things we need to handle when finding the previous match.
In a Leaf node, we return SOME if the argument index is greater than the interval’s startIdx, or else we return NONE.
In a Concat node, if we recurse down the right child and see that the result is NONE, we return the largest interval in the left child.
The meaning of these two rules is: if the cursor is after the interval’s start, then return this interval; otherwise, return the previous interval if one exists.
The way we handle the Leaf case here is different than when retrieving the next match, because the interval we retrieve may contain the argument index we pass to it, while that will never happen when retrieving the next match.
The code below implements the prevMatch function.
fun largestInterval (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
| Concat (left, weight, right) => largestInterval (index, right, acc + weight)
fun helpPrevMatch (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
if index > startIdx then
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
else
NONE
| Concat (left, weight, right) =>
if index < weight then
helpPrevMatch (index, left, acc)
else
case helpPrevMatch (index, right, acc + weight) of
SOME interval => SOME interval
| NONE => largestInterval (index, left, acc)
fun prevMatch (index, rope) =
case rope of
SOME rope => helpPrevMatch (index, rope, 0)
| NONE => NONE
There are, again, helper functions here. They have a similar purpose to the helper functions for finding the next match.
Since getting the previous match is part of the public API, we unwrap the Rope from an option type.
Deleting from an Interval Rope
We will first cover how to delete from an Interval Rope. We follow a simple multi-step process:
- We get the next match’s
startIdx, after the deletion point’s end - We split the Interval Rope into left and right halves
- We decrement the right half so that its absolute index is equal to the match index we got in step 1, minus the length of the deletion
- We concatenate the left half with the new right half and return it
This is rather simple. The only step that might give confusion is the third one. Why do we decrement the right half? To keep the metadata in the Interval Rope consistent with the underlying text.
The diagram below illustrates how the Interval Rope can become inconsistent without decrementing, and how decrementing can fix the inconsistency.
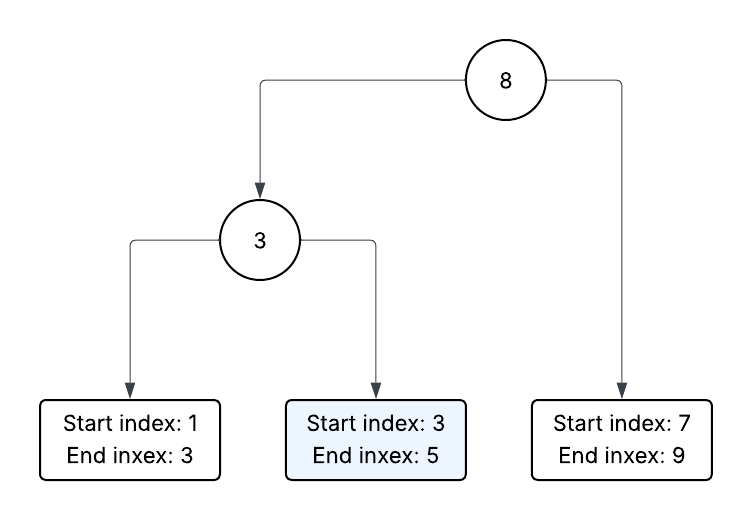
The above diagram shows an Interval Rope with the middle Leaf highlighted, We can delete this node, which has a length of 2 (5 - 3 = 2), by splitting, which means that splitting lets us delete a length of 2.
What if we wanted to delete a length of 3 instead though? Splitting won’t let us do that, but splitting (thus deleiting 2) and then decrmenting the first node in the right split by 1 will. This is our reason for decremnting: we cannot delete the length we want to without it.
The code below implements the delete function. There is some trivial edge-case handling that is not described in the steps above.
fun delete (index, length, rope) =
case rope of
SOME rope =>
let
val endIdx = index + length
in
(* get next match and split rope into two halves, if possible *)
case nextMatch (endIdx, rope) of
SOME {startIdx = nextMatchStartIdx, ...} =>
let
val left = splitKeepingStart (index, rope)
val right = splitKeepingEnd (endIdx, rope)
val newRightStartIdx = nextMatchStartIdx - length
in
case (left, right) of
(SOME left, SOME right) =>
(* can split into two halves *)
let
(* calculate absolute index of interval at start of right rope *)
val leftEndIdx = uLargestIdx (left, 0)
val rightStartIdx = smallestIdx right + leftEndIdx
(* calculate length to decremens by *)
val decrementBy = rightStartIdx - newRightStartIdx
in
(* decrement right, and then concatenate it with left *)
SOME (concatenate (
left,
decrement (decrementBy, right)
))
end
| (SOME left, NONE) =>
(* return left, because there is no interval in right, ss nothing to decrement *)
SOME left
| (NONE, SOME right) =>
let
(* calculate how much to decrement by, and then decrement without joining, because there are no intetvals to join with in left *)
val rightStartIdx = smallestIdx right
val decrementBy = rightStartIdx - newRightStartIdx
in
SOME (decrement (decrementBy, right))
end
| (NONE, NONE) =>
(* no valid intervals in left or right, so return NONE *)
NONE
end
| NONE =>
(* no matches to decremens after endIdx, so just split left *)
splitKeepingStart (index, rope)
end
| NONE =>
(* rope is empty, so there are no intervals to delete, so return NONE *)
NONE
There are a number of comments in the above code, to describe edge cases and what the code is doing. Our four-step process described above focuses on the happy path where intervals exist after splitting the Rope, and there is a match after the deletion range. The edge cases explain what we do if those conditions don’t hold.
Inserting into an Interval Rope
We expect that the user has called incrementAt to increment intervals subsequent to the index where text was inserted, before inserting into the Interval Rope.
There is another a multi-step process for inserting into an Interval Rope, which is as follows:
- Split the Interval Rope into left and right halves
- Calculate the difference between the end index we wish to insert and the end index of the left Rope
- Concatenate the interval we wish to insert to the left Rope
- Decrement the right Rope by the difference calculated in step 2
- Concatenate the new left half (which contains the interval we wanted to insert) with the decremented right half
The reason we decrement in the fourth step is because the absolute indices are impacted by our insertion, and decrementing in this way ensures that the absolute indices stay the same. Apart from that, these steps are all fairly straight-forward.
The code below implements this.
fun insert (intervalStartIndex, intervalEndIndex, rope) =
case rope of
SOME rope =>
let
val left = splitKeepingStart (intervalStartIndex, rope)
val right = splitKeepingEnd (intervalEndIndex, rope)
in
case (left, right) of
(SOME left, SOME right) =>
(* can split into two halves *)
let
val leftEndIdx = uLargestIdx (left, 0)
val decrementBy = intervalEndIndex - leftEndIdx
(* decrement new interval by leftEndIdx so that its relative index inside the rope is the same as the absoute index passed in as an argument *)
val newInterval =
Leaf {startIdx = intervalStartIndex - leftEndIdx, endIdx = intervalEndIndex - leftEndIdx}
val newLeft = concatenate (left, newInterval)
val newRight = decrement (decrementBy, right)
in
SOME (concatenate (newLeft, newRight))
end
| (SOME left, NONE) =>
(* can't split right, so just concatenate to left *)
let
val leftEndIdx = uLargestIdx (left, 0)
val newInterval =
Leaf {startIdx = intervalStartIndex - leftEndIdx, endIdx = intervalEndIndex - leftEndIdx}
in
SOME (concatenate (left, newInterval))
end
| (NONE, SOME right) =>
(* decrement right by end of new interval, and then concatenate *)
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
val newRight = decrement (intervalEndIndex, right)
in
SOME (concatenate (newInterval, newRight))
end
| (NONE, NONE) =>
(* no intervals remain after splitting, so just return new interval *)
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
in
SOME newInterval
end
end
| NONE =>
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
in
SOME newInterval
end
The code above does have some edge cases which are commented. The only edge case which might be a little tricky to understand is when we can get a right by splitting, but not a left half.
In that case, we can consider that the right half implicity has a weight of 0 to the left, and that concatenating the new interval to the left will cause the weight to be incremented by the new interval’s end index.
Because of this logic, we know that we cen restore the original absolute indices by decrementing the right half by the new interval’s end index, so that is what we do.
We have now finished implementing our Interval Rope
Full Interval Rope Code
The full source code for the Interval Rope is below.
signature INTERVAL_ROPE =
sig
type t
val empty: t
val hasIntervalAtIndex: int * t -> bool
val prevMatch: int * t -> {startIdx: int, endIdx: int} option
val incrementAt: int * int * t -> t
val delete: int * int * t -> t
val insert: int * int * t -> t
end
structure IntervalRope :> INTERVAL_ROPE =
struct
datatype interval_rope =
Concat of interval_rope * int * interval_rope
| Leaf of {startIdx: int, endIdx : int}
type t = interval_rope option
val empty: t = NONE
fun uHasIntervalAtIndex (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
startIdx <= index andalso endIdx >= index
| Concat (left, weight, right) =>
if index <= weight then
uHasIntervalAtIndex (index, left)
else
uHasIntervalAtIndex (index - weight, right)
fun hasIntervalAtIndex (index, rope) =
case rope of
SOME rope => uHasIntervalAtIndex (index, rope)
| NONE => false
fun uLargestIdx (rope, acc) =
case rope of
Leaf {startIdx, endIdx} => endIdx + acc
| Concat (left, weight, right) =>
uLargestIdx (right, acc + weight)
fun largestIdx rope =
case rope of
SOME rope => uLargestIdx (rope, 0)
| NONE => 0
fun smallestIdx rope =
case rope of
Leaf {startIdx, endIdx} => startIdx
| Concat (left, weight, right) => smallestIdx left
fun concatenate (left, right) =
Concat (left, uLargestIdx (left, 0), right)
fun splitKeepingStart (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
if index > endIdx then
SOME rope
else
NONE
| Concat (left, weight, right) =>
if index <= weight then
splitKeepingStart (index, left)
else
let
val result = splitKeepingStart (index - weight, right)
in
case result of
SOME newRight => SOME (Concat (left, weight, newRight))
| NONE => SOME left
end
fun splitKeepingEnd (index, rope) =
case rope of
Leaf {startIdx, endIdx} =>
if index < startIdx then
SOME rope
else
NONE
| Concat (left, weight, right) =>
if index <= weight then
case splitKeepingEnd (index, left) of
SOME newLeft => SOME (Concat (newLeft, uLargestIdx (newLeft, 0), right))
| NONE => SOME right
else
splitKeepingEnd (index - weight, right)
fun decrement (decrementBy, rope) =
case rope of
Leaf {startIdx, endIdx} =>
Leaf {
startIdx = startIdx - decrementBy,
endIdx = endIdx - decrementBy
}
| Concat (left, weight, right) =>
let
val newLeft = decrement (decrementBy, left)
val newWeight = weight - decrementBy
in
Concat (newLeft, newWeight, right)
end
fun increment (incrementBy, rope) =
case rope of
Leaf {startIdx, endIdx} =>
Leaf {
startIdx = startIdx + incrementBy,
endIdx = endIdx + incrementBy
}
| Concat (left, weight, right) =>
let
val newLeft = increment (incrementBy, left)
val newWeight = weight + incrementBy
in
Concat (newLeft, newWeight, right)
end
fun incrementAt (idx, incrementBy, rope) =
case rope of
SOME rope =>
let
val left = splitKeepingStart (idx, rope)
val right = splitKeepingEnd (idx, rope)
in
case (left, right) of
(SOME left, SOME right) =>
let
val newRight = increment (incrementBy, right)
in
SOME (concatenate (left, newRight))
end
| (SOME left, NONE) =>
(* nothing to increment since no intervals after index *)
SOME left
| (NONE, SOME right) =>
(* just incremet right and return without concatenating, since there is no left *)
SOME (increment (incrementBy, right))
| (NONE, NONE) =>
(* nothing remains after splitting, so return nothing *)
NONE
end
| NONE => NONE
fun smallestInterval (rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
{startIdx = startIdx + acc, endIdx = endIdx + acc}
| Concat (left, weight, right) => smallestInterval (left, acc)
fun helpNextMatch (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
if index < startIdx then
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
else
NONE
| Concat (left, weight, right) =>
if index < weight then
case helpNextMatch (index, left, acc) of
SOME interval => SOME interval
| NONE => SOME (smallestInterval (right, acc + weight))
else
helpNextMatch (index - weight, right, acc + weight)
fun nextMatch (index, rope) = helpNextMatch (index, rope, 0)
fun largestInterval (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
| Concat (left, weight, right) => largestInterval (index, right, acc + weight)
fun helpPrevMatch (index, rope, acc) =
case rope of
Leaf {startIdx, endIdx} =>
if index > startIdx then
SOME {startIdx = startIdx + acc, endIdx = endIdx + acc}
else
NONE
| Concat (left, weight, right) =>
if index < weight then
helpPrevMatch (index, left, acc)
else
case helpPrevMatch (index, right, acc + weight) of
SOME interval => SOME interval
| NONE => largestInterval (index, left, acc)
fun prevMatch (index, rope) =
case rope of
SOME rope => helpPrevMatch (index, rope, 0)
| NONE => NONE
fun delete (index, length, rope) =
case rope of
SOME rope =>
let
val endIdx = index + length
in
(* get next match and split rope into two halves, if possible *)
case nextMatch (endIdx, rope) of
SOME {startIdx = nextMatchStartIdx, ...} =>
let
val left = splitKeepingStart (index, rope)
val right = splitKeepingEnd (endIdx, rope)
val newRightStartIdx = nextMatchStartIdx - length
in
case (left, right) of
(SOME left, SOME right) =>
(* can split into two halves *)
let
(* calculate absolute index of interval at start of right rope *)
val leftEndIdx = uLargestIdx (left, 0)
val rightStartIdx = smallestIdx right + leftEndIdx
(* calculate length to decremens by *)
val decrementBy = rightStartIdx - newRightStartIdx
in
(* decrement right, and then concatenate it with left *)
SOME (concatenate (
left,
decrement (decrementBy, right)
))
end
| (SOME left, NONE) =>
(* return left, because there is no interval in right, ss nothing to decrement *)
SOME left
| (NONE, SOME right) =>
let
(* calculate how much to decrement by, and then decrement without joining, because there are no intetvals to join with in left *)
val rightStartIdx = smallestIdx right
val decrementBy = rightStartIdx - newRightStartIdx
in
SOME (decrement (decrementBy, right))
end
| (NONE, NONE) =>
(* no valid intervals in left or right, so return NONE *)
NONE
end
| NONE =>
(* no matches to decremens after endIdx, so just split left *)
splitKeepingStart (index, rope)
end
| NONE =>
(* rope is empty, so there are no intervals to delete, so return NONE *)
NONE
fun insert (intervalStartIndex, intervalEndIndex, rope) =
case rope of
SOME rope =>
let
val left = splitKeepingStart (intervalStartIndex, rope)
val right = splitKeepingEnd (intervalEndIndex, rope)
in
case (left, right) of
(SOME left, SOME right) =>
(* can split into two halves *)
let
val leftEndIdx = uLargestIdx (left, 0)
val decrementBy = intervalEndIndex - leftEndIdx
(* decrement new interval by leftEndIdx so that its relative index inside the rope is the same as the absoute index passed in as an argument *)
val newInterval =
Leaf {startIdx = intervalStartIndex - leftEndIdx, endIdx = intervalEndIndex - leftEndIdx}
val newLeft = concatenate (left, newInterval)
val newRight = decrement (decrementBy, right)
in
SOME (concatenate (newLeft, newRight))
end
| (SOME left, NONE) =>
(* can't split right, so just concatenate to left *)
let
val leftEndIdx = uLargestIdx (left, 0)
val newInterval =
Leaf {startIdx = intervalStartIndex - leftEndIdx, endIdx = intervalEndIndex - leftEndIdx}
in
SOME (concatenate (left, newInterval))
end
| (NONE, SOME right) =>
(* decrement right by end of new interval, and then concatenate *)
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
val newRight = decrement (intervalEndIndex, right)
in
SOME (concatenate (newInterval, newRight))
end
| (NONE, NONE) =>
(* no intervals remain after splitting, so just return new interval *)
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
in
SOME newInterval
end
end
| NONE =>
let
val newInterval =
Leaf {startIdx = intervalStartIndex, endIdx = intervalEndIndex}
in
SOME newInterval
end
fun helpToList (rope, listAcc, weightAcc) =
case rope of
Leaf {startIdx, endIdx} =>
{startIdx = startIdx + weightAcc, endIdx = endIdx + weightAcc} :: listAcc
| Concat (left, weight, right) =>
let
val listAcc = helpToList (right, listAcc, weightAcc + weight)
in
helpToList (left, listAcc, weightAcc)
end
fun toList rope =
case rope of
SOME rope => helpToList (rope, [], 0)
| NONE => []
end
(* insertion tests *)
val r1 = IntervalRope.insert (7, 9, NONE)
val r1Pass =
IntervalRope.toList r1 = [{startIdx = 7, endIdx = 9}]
val r2 = IntervalRope.insert (1, 1, r1)
val r2Pass =
IntervalRope.toList r2 = [{startIdx = 1, endIdx = 1}, {startIdx = 7, endIdx = 9}]
val r3 = IntervalRope.insert (3, 5, r2)
val r3Pass =
IntervalRope.toList r3 = [{startIdx = 1, endIdx = 1}, {startIdx = 3, endIdx = 5}, {startIdx = 7, endIdx = 9}]
val r4 = IntervalRope.insert (13, 15, r3)
val r4Pass =
IntervalRope.toList r4 = [{startIdx = 1, endIdx = 1}, {startIdx = 3, endIdx = 5}, {startIdx = 7, endIdx = 9}, {startIdx = 13, endIdx = 15}]
(* deletion tests *)
(* decrements last interval from 13-15 by 1, changing it to 12-14 *)
val r5 = IntervalRope.delete (11, 1, r4)
val r5Pass =
IntervalRope.toList r5 = [{startIdx = 1, endIdx = 1}, {startIdx = 3, endIdx = 5}, {startIdx = 7, endIdx = 9}, {startIdx = 12, endIdx = 14}]
(* deletes last interval *)
val r6 = IntervalRope.delete (11, 5, r4)
val r6Pass =
IntervalRope.toList r6 = [{startIdx = 1, endIdx = 1}, {startIdx = 3, endIdx = 5}, {startIdx = 7, endIdx = 9}]
(* deletes first interval and decrements subsequent ones *)
val r7 = IntervalRope.delete (1, 1, r4)
val r7Pass =
IntervalRope.toList r7 = [{startIdx = 2, endIdx = 4}, {startIdx = 6, endIdx =
8}, {startIdx = 12, endIdx = 14}]
(* deletes middle interval and decrements subsequent ones *)
val r8 = IntervalRope.delete (3, 2, r4)
val r8Pass =
IntervalRope.toList r8 = [{startIdx = 1, endIdx = 1}, {startIdx = 5, endIdx = 7}, {startIdx = 11, endIdx = 13}]
Using the Interval Rope
Okay, we have our Interval Rope implemented and tested now, but how do we use it to keep track of search-matches in some text?
There won’t be any code now; that will be an exercise to the reader.
How to Insert
When we want to insert a match that came from inserting into the underlying text, we:
- Call
incrementAtwith the index we inserted the string at and the length of the string that we inserted - Call
prevMatchwith the Rope returned after incrementing it in step (1) - Search the underlying text for matches from the prevMatch index in a loop, inserting every match we find, returning when we reach a match that already exists in the Rope
The third step is a little vague on details, since the prevMatch function returns two indices (the start and end indices of the interval). Which index do we start iterating from?
That partly depends on what kind of search we want to perform. If it is a regex search like “o+”, then the previus match may possibly extend and become longer. If we insert “o” into a text containing “ooo”, then our match will become longer by 1.
We can account for this case by deleting the interval returned from calling prevMatch and starting our loop from step (3) at the match’s start index. Alternatively, if the regex engine’s internals are exposed to us and we can see the final/accept state that the interval ended at, we can start looping at the end index + 1, feeding our interval’s accept state as the initial state to the loop.
This question is easier to answer if we do a plain text search though. We always start our loop at the interval’s end index + 1, because there is no way the match will extend.
Finally, the loop in step (3) can have the same worst-case time-complexity as finding all matches from scratch. Consider searcing for “z” and having only one match at the start of the document in a document with a million lines, We will basically need to search for all matches from the start to the end.
In practice, I have never noticed any performance problems in the loop, so I don’t worry about it, but a better way might exist. This problem stems from our search algorithm rather than from how Interval Ropes work in any event.
How to delete
Deletion is similar to insertion.
- Call the
deletefunction with the index we want to start deleting at and the length we want to delete - Call
prevMatchfrom the deletion’s start index - Search for and insert matches, starting from
prevMatchuntil we find a match that already exists, in a loop
The distinction between regex and plaintext search still applies here. The comments regarding the worst-case time complexity also apply.
Conclusion
While I discovered Interval Ropes independently, I wasn’t the first to do so. In the introduction to his Rope Science series of posts, Raph Levien mentions wanting to write about Ropes and Interval Trees, but never did so. He probably had a similar data structure in mind to the one this blog post is about.
The real stars of the game, in my opinion, are classic String-based Ropes, which may lend themselves to a wide range of uses beyond manipunating text (including uses not yet known), as well as the power to think and understand, which gives us the ability to solve problems that were not previously known to have a solution.
“I should not like my writing to spare other people the trouble of thinking. But, if possible, to stimulate someone to thoughts of his own.” - Ludwig Wittgenstein
The Cedar programming community, where Ropes were first created, reminds me of the above quote because they have certainly stimulated me to thoughts of my own. I hope this blog post encourages others to think and develop new ideas too.